Abstract
Introduction
In this report we will investigate the usefulness of tag clouds for increasing user performance with search engines. Similar research has been done before, for example by Kuo et al. (2007). By presenting the users with several questions they have to answer, we hope to find a significant difference in performance between a traditional interface and an interface augmented with tag cloud widgets.
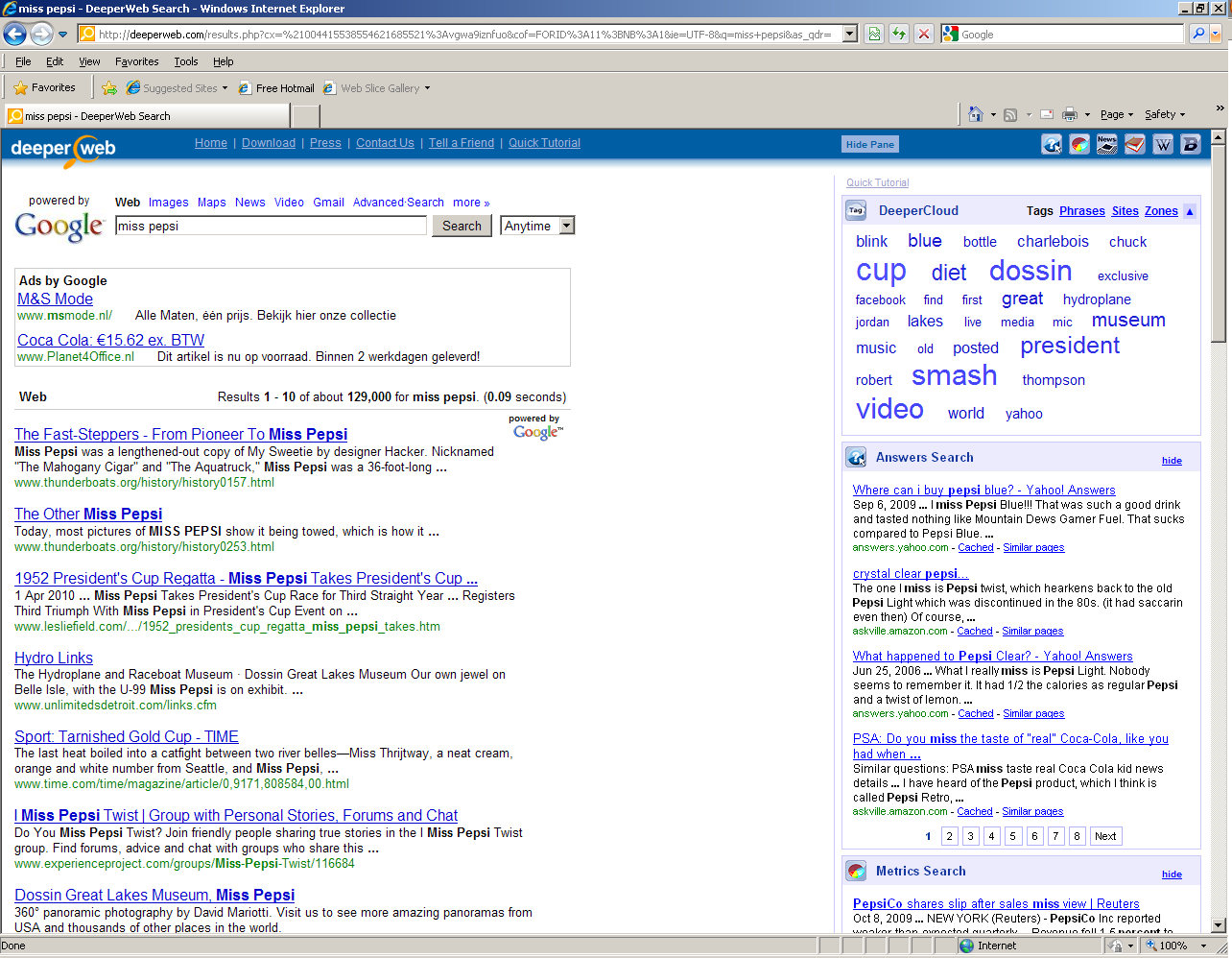
We found such an application in www.deeperweb.com which augments Google's standard search results with a tag cloud. Thus comparing Google and Deeperweb is a very good way to investigate the effects of tag clouds on user performance, as this eliminates search engine performance from having an effect on user performance.
Background
Internet searches
With the rise of the internet, the information age started. Through a virtual web, people got the opportunities to look at billions of webpages with information. To find the right information, people have to use a filtering system. The most successful information retrieval systems on the web have been the search engines. Because of that the most successful search engine, Google, has managed to build a multi-billion dollar imperium.
The most common way to find information across the World Wide Web is by using of search engines. Google is the most popular search engine and performs millions of searches per day. It has gained a market share of over 70% in the US (Garner, 2009)and even over 90% in the Netherlands (Chekit, 2010).
Although Google does not rank the most relevant results at the top, it does have a high degree of usability (van Zwol & van Oostendorp, 2004), which could very well explain the high market share. So although they have a high market share, there is still room for improvement.
Tag clouds
Tag clouds are another way to show a summary of content to users. Tag clouds gather the most common keywords out of a field of content. Therefore people can find information that is hidden deep down a website or web page (Kuo et al., 2007). Tag clouds are still very primitive, but can in the future be developed to help users navigate across the web. An improvement of the tag clouds can be in categorization.
Research from Sinclair & Cardew-Hall (2008) showed when tag clouds can best be used. Results showed that tag clouds are particularly useful when people are searching for a broad subject. Tags should be used for categorization. They gave users an idea of the domain and so could help people with refining their queries. But users commented that the tag cloud was not suitable for finding specific information. Finally, using tags for refining your query requires less cognitive load for a user.
Through visualization methods tag clouds can show more information (Lohmann et al., 2009). Large tags attract more attention than small tags. Tags in the center of the cloud will get more attention than tags at the borders. Further, tags in the upper left quadrant will be found more quickly and are more likely to be recalled. Users scan the cloud more than actually reading it and the layout has a big influence on the users perception.(Rivadeneira et al., 2007; Bateman et al., 2008)
Motivation
Spink et al. (2001) studied trends in web search behavior. They concluded that the interaction of a user with a search engine was short and limited. They pleaded for a generation of more interactive searching tools. Meanwhile, the major search engine Google hasn't changed much.
It is necessary that search engines help people reduce the information complexity (Kao et al., 2008) and provide individual information to users and present the results in ways that are easier to understand.
An experimental search engine was created where search results where combined with a tag cloud of semantically related result (Mirizzi et al., 2010). Although there are a lot of arguments that these tags could help the users to refine their queries, there is still no empirical evidence that confirms these ideas.
Deeperweb
In this research we will look at the implications that Deeperweb has. Does a combination of a tag cloud really help users to find information across the internet and will users accept such a tool? Therefore the following hypotheses are being tested.
Hypotheses
- H1
- Deeperweb decreases the amount of time needed to find a satisfactory answer
- H2
- Deeperweb decreases the number of page visits needed to find a satisfactory answer
- H3
- Participants using Deeperweb will use more queries to find a satisfactory answer
- H4
- Participants using Deeperweb will give up less
- H5
- Participants are most satisfied with the best performing search engine
- H6
- User experience influences performance positively
- H7
- User experience influences both conditions equally
Method
To be able to support our hypotheses we set up an experiment in which participants were randomly assigned to either Google or Deeperweb. Users were welcomed by the experimenter and given written instructions2 , which basically said that they should not follow links on the pages found by the search engine. They were also told that we would capture the screen output and that each task would take about five minutes.
Using either of the search engines they were asked to find the answers to six questions. The first was a training question, to get used to the kind of question and the search engine. The following five were administered in random order to cancel out any possible learning effects. Administration took place via a PHP script, which also recorded the time needed to find a satisfactory answer. Users were also asked to submit these answers and the URLs on which they found it. The questions were:
- What was the real name of the singer Pepsi? 3
- In what dance is a controversial Spanish tradition represented?
- What 1929 car gave rise to an expression still used today?
- How was mister Coke involved in the second world war?
- What was miss Coca famous for?
- Who was president of Bolivia in 1995?
The questions were constructed in such a way that it was unlikely that participants knew the answer and that the answer would not appear on the first page of hits when using keywords from the sentence. In doing so we hoped to stimulate the users to reevaluate their original queries either by coming up with new search terms by themselves or by using the tag cloud in Deeperweb.
After the participants had completed the tasks they were asked to fill out a survey (see appendixB) in order to find out information like experience with search engines and their satisfaction with the used search engine.
The screen captures were later analyzed using InqScribe4 to retrieve data about the number of pages visited, the number of queries used and the number of times the tagcloud was used.
The experiments took place in the ``Sterrenzaal'' in the Minnaert building of Utrecht University. Although the environment was not under our control, experience told us that this was a quiet room with adequate facilities and minimum chance of being disturbed.
Results
From our survey we learned that all of the valid results were people with an information science background. This possibly contributed to the high number of searches they performed (14,8 searches per day on average) and the amount of time they spend on the internet (on average 4 hours and 50 minutes).
Time
Levene's test revealed that for all measured times, the variances are equal. See appendix C.1.
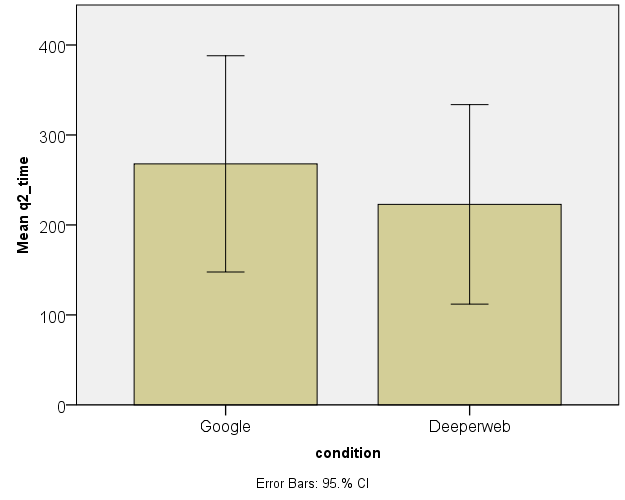
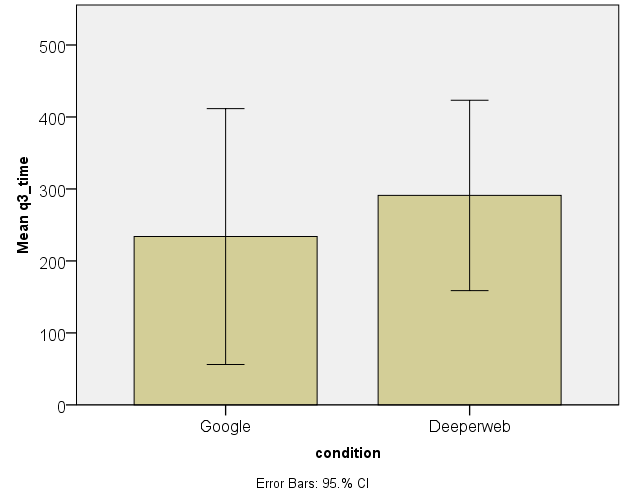
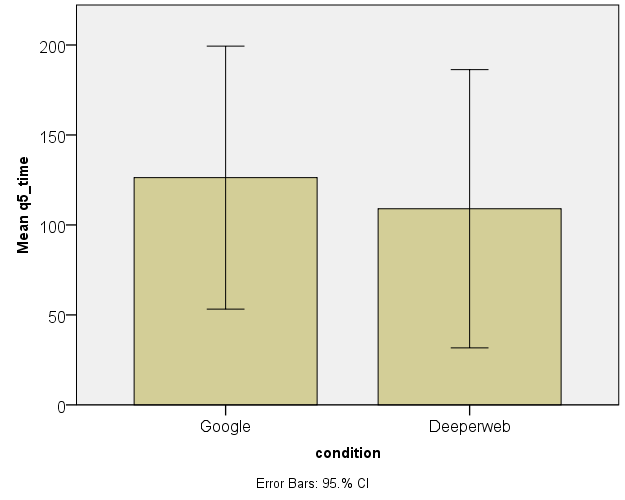
The normally distributed results were checked visually using bar charts with 95% confidence intervals plotted on them (see figures 1, 2 and 3). This revealed that confidence intervals overlapped for a large part, meaning that there is no significant difference in performance for questions 2, 3 and 5.
For questions 1 and 4 and the total time users needed we perform a Mann-Whitney test in order to investigate if difference between the means exist. (See table 2)
Performance for question 1 ( Mdngoogle= 184, Mdndeeperweb = 126) did not differ significantly between conditions U = 20.000, z = -.143, ns, r = -.04. Also for question 4 ( Mdngoogle= 103, Mdndeeperweb = 90; U = 19.000, z = -.286, ns, r = -.08) and the total time needed for questions 1 through 5 (( Mdngoogle = 728.00, Mdndeeperweb = 730.50 ; U = 19.000, z = -.286, ns, r = -.08) no significant differences have been found.
Queries and page visits
Analyzing the number of page visits, we found that participants in both conditions have almost exactly the same average number of page visits. Mgoogle = 12.29 and Mdeeperweb = 12.33. As could be expected from this small difference, the t-test revealed that it was not significant t(11) = -.011, p > .05.
Using a Mann-Whitney test to analyze the number of queries performed in total by participants, we found that there is no significant difference between conditions ( Mediangoogle=18, Mediandeeperweb=16,50). U = 19, z = -.288, ns (see table 4
Satisfaction
Knowing this we feel confident that we can use either measure of satisfaction to test our hypothesis concerning user satisfaction and which engine they used. We choose to use the measure built up of the indirect questions, as investigating peoples minds is generally better done indirectly.
Using a Shapiro-Wilk test we found that the values are normally distributed ( Df(13), p > .05), which means we can use a t-test to compare the results. Doing so taught us that the minimal difference between user satisfaction for participants that used Google ( M = 3.49, SE=0.49) and that used Deeperweb ( M = 3.62, SE=0.58) was not significant t(11) = -.436, p = .671 and has only a minor effect r = .13$. (see appendix C.3)
Experience
As such, we are able to investigate the correlation between these variables using Pearson's r. This showed that no significant correlation exists between total number of queries needed and number of searches per day or hours spent on the internet per day. (See table 7)
In order to test whether a relationship exists between any of the other variables, numbers of searches per day, number of hours on the internet per day, total number of pages visited and total time needed to complete the questions, we need to use a non parametric test like Spearman's ρ. Unfortunately this also did not reveal any significant correlations between the variables we wanted to test. (See table 8)
What is revealed in both analyses though, is that there is a correlation between time spent on the internet and number of searches per day. r=.624, p<.05, R2=.389 Interesting though this is, it is neither surprising nor what we were looking for.
Failures
A Shapiro-Wilk test revealed that our data for this hypothesis are not normally distributed ((D13), P < .05). Levene's test showed that the assumption of homogeneity of variance has not been violated (F(1,11) = 1.47, ns). This mean that we have to use a Mann-Whitney test to investigate the difference in means.
The number of questions given up on by users in both conditions Mdngoogle = 1, Mdndeeperweb = 0 did not differ significantly (see table 9). There is a medium sized effect though. U = 8.500, z = -1.977, ns, r = -.548
Discussion
The research did not deliver the results as we expected. For this there are a couple of factors that can have influenced the results.
For this research we have tested 18 participants. All participants had an age between 18 and 30, were higher educated and had experience in computer science. The survey showed that the participants perform a lot of searches and spend a lot of time on the internet. A larger and more diverse sample could have made a difference. Because people have experience and are used to search with Google, the need for another search engine can be low.
The search tasks the participants had to perform where made up. The questions where supposed to be found after the use of multiple queries, which turned out pretty well. However, the questions were quite ambiguous and therefore sometimes hard to understand. Participants had to search for very specific information, although tag clouds proved more useful for broad categorization. The influence of Deeperweb on less specific tasks remains unknown.
In this research we haven't checked the answers people gave to the questions. The assumption was made that users would give a satisfactory answer. Through to the enormous amount of information it is hard to say if an answer is right or wrong. Some answers were definitely right, others were definitely wrong. Some of the answers were harder to define. To define these answers as right or wrong, issues like web credibility come to play.
Participants who performed the tasks all spoke Dutch as first language. Everyone knew English as a second language. The tasks where performed in English, because Deeperweb is based on Google in English. Participants who spoke English as a first language could give other results.
In this experiment only short term effects of the tag cloud were registered. People didn't have any experience with Deeperweb. In the long term, Deeperweb might show better results because people learn to work effective with it. Therefore a longer and ``deeper'' research is needed.
The exact impact of the tag cloud on the searches performed is not totally clear. We have measured the number of clicks on tags, but the inspiration that the tag cloud gave to type in new queries is unknown. In most researches about tag clouds, eye-tracking software is being used, to see the influence. Use of eye-tracking software can also show if Deeperweb can be improved through changing the layout or the positioning of the tag cloud.
Conclusion
Tags can be used to improve search queries (Sinclair & Cardew-Hall, 2008) . Deeperweb uses a tag cloud to refine queries for the Google search engine. This research showed that there are no significant differences in the time people have to spend searching for an answer to a question between Deeperweb and Google. There were also no differences found in the user satisfaction of both tools. The differences in results between both test groups were minimal. Therefore it makes no sense to continue this research as it is.
Still there are some leads for future research. The Deeperweb tag cloud gives a quick overview of the keywords out of the results. It gives the user more information to find information. How users respond to this is an interesting phenomenon. Issues like layout, web credibility, type of task and user experience will all play their role in the use of deeperweb. At least we can say one thing for sure. Web search is still not fully optimized and there's still room for improvement. The search for better search tools should continue.